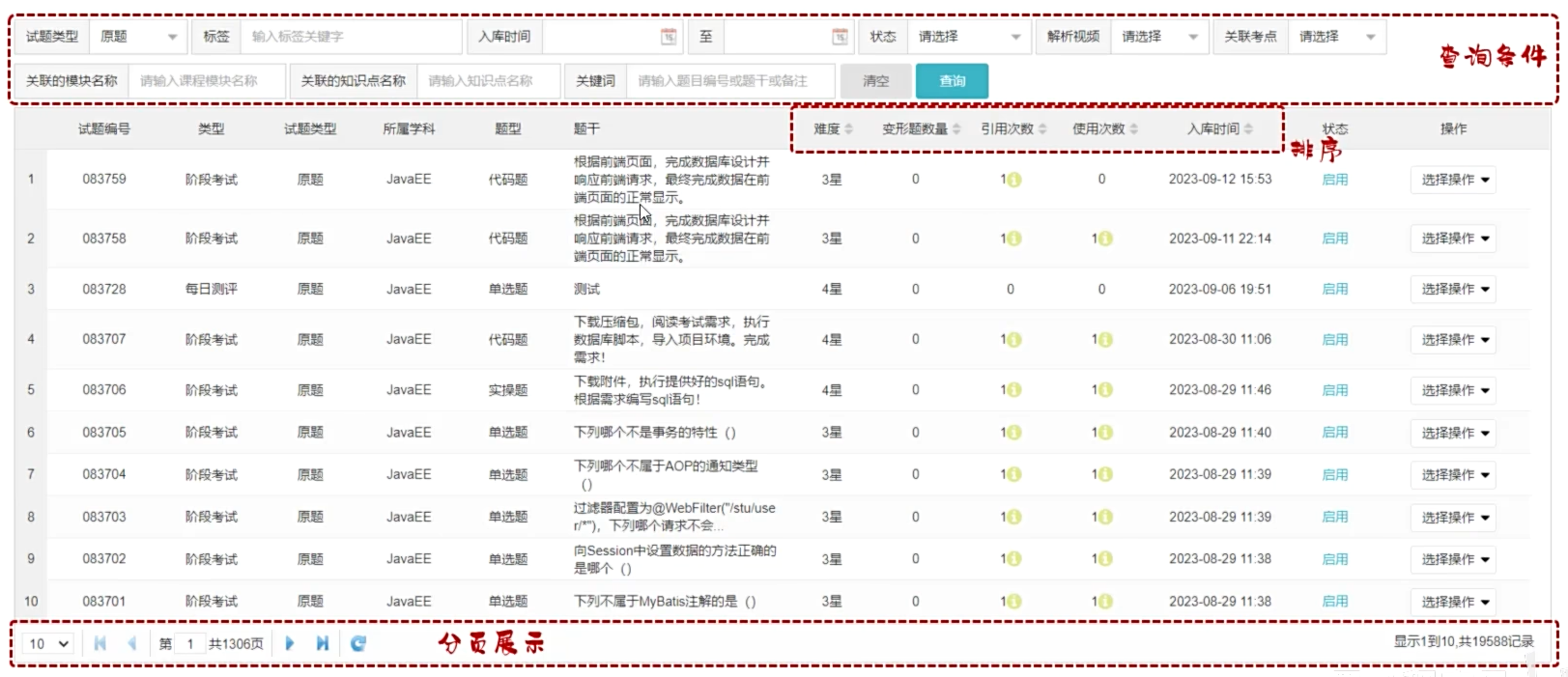
Day05 数据库
什么是数据库?
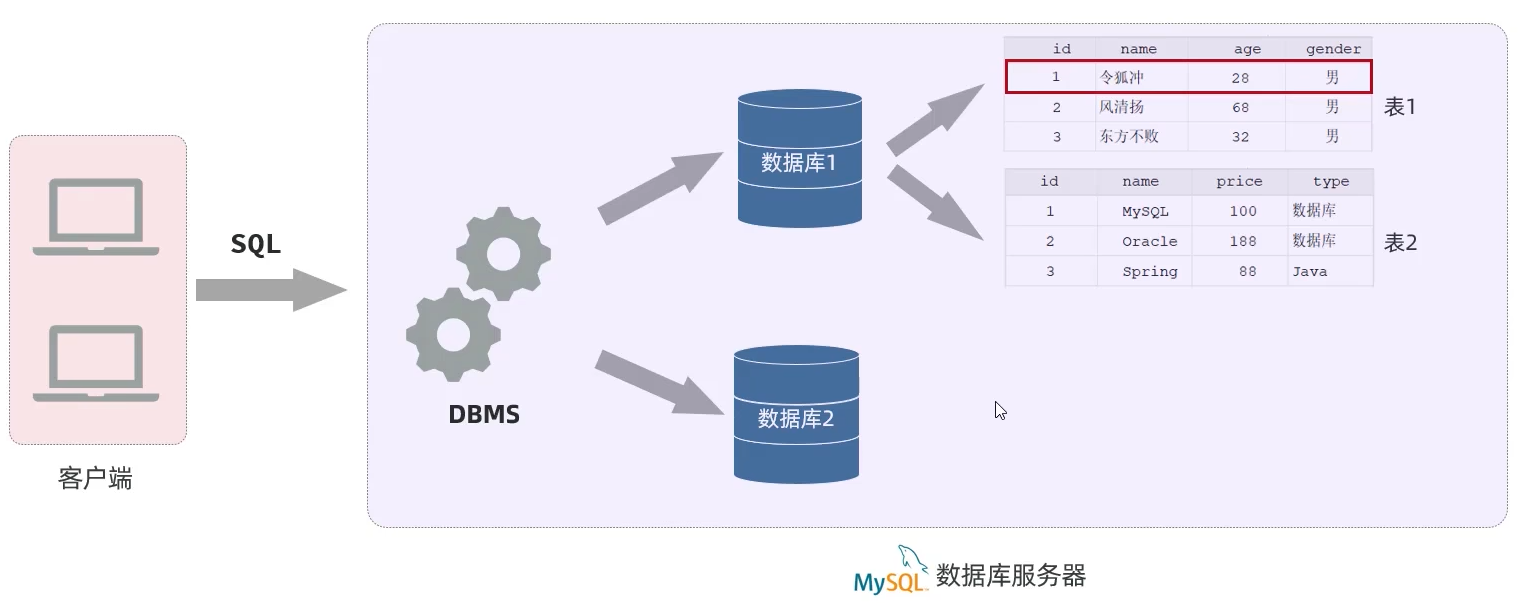
数据库:DataBase(DB),是存储和管理数据的仓库。
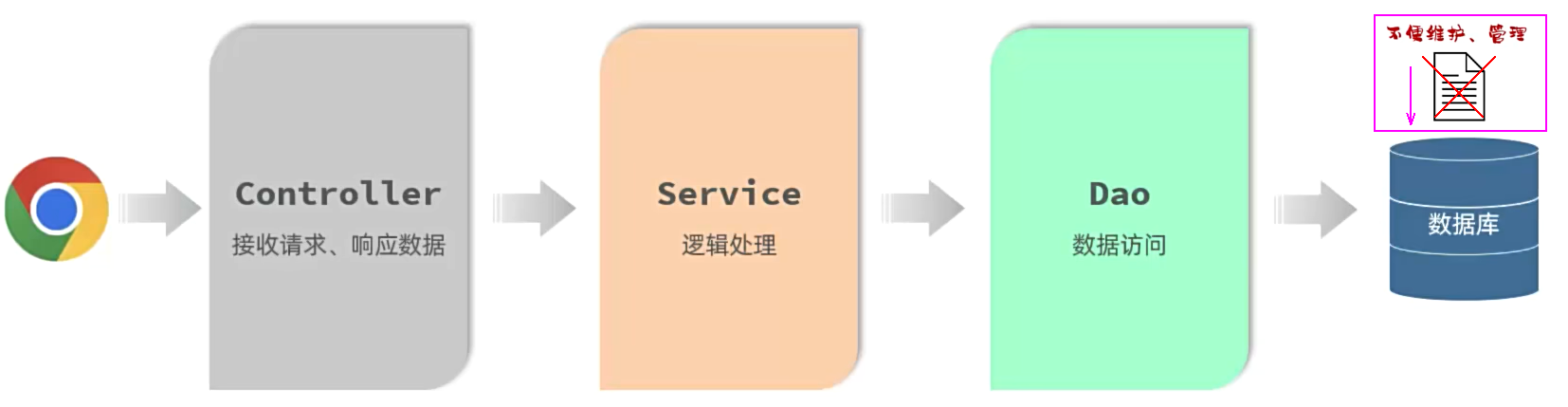
数据库管理系统:DataBase Management System(DBMS),操纵和管理数据库的大型软件。
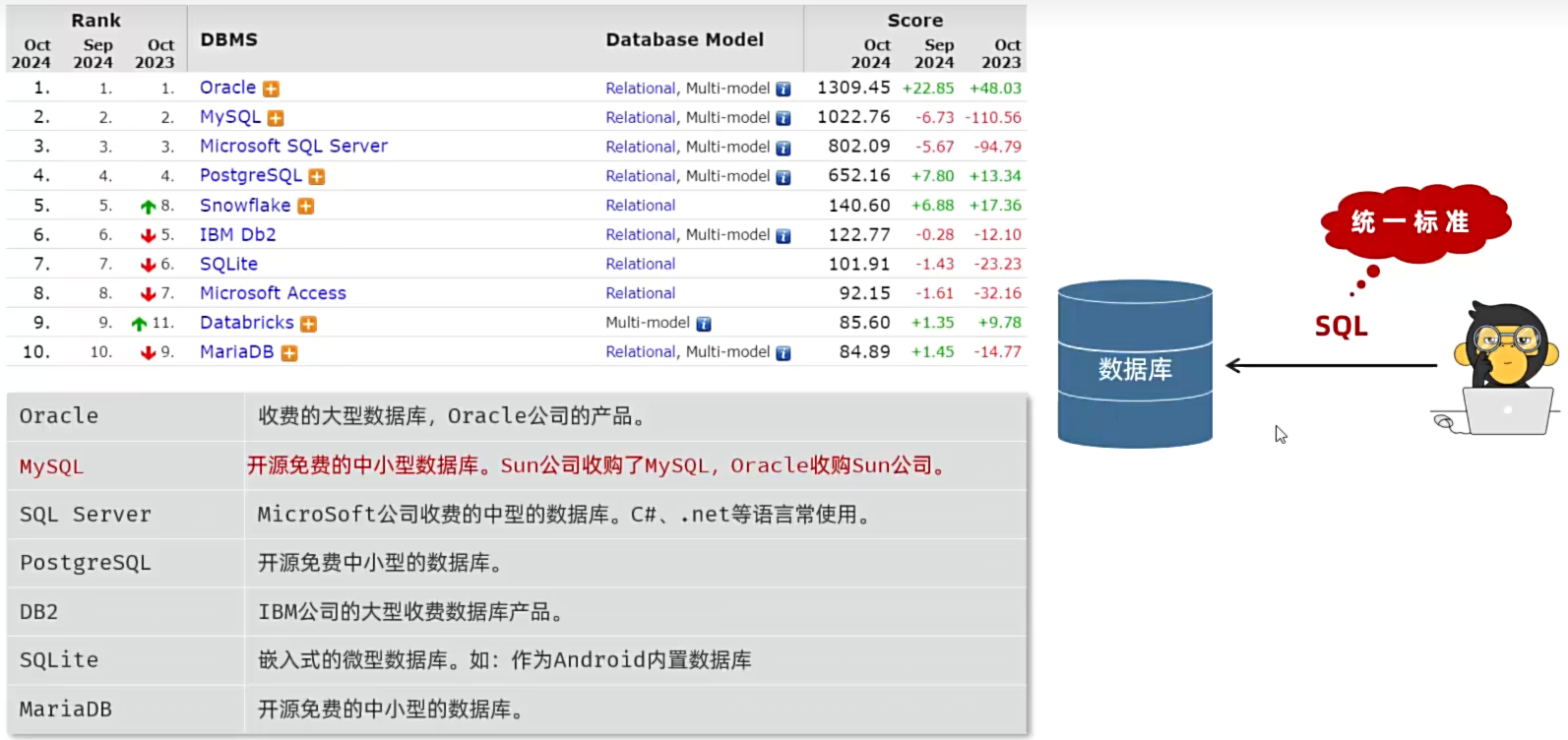
SQL:Structured Query Language,操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准。
数据库产品
目录
- MySQL概述
- SQL语句
- 多表设计
- 多表查询
- 事务与优化
今天只学习前两部分
1. MySQL概述
1.1 安装
MySQL安装
- MySQL官方提供了两种不同的版本:

图4 MySQL的两种版本 - 本课程采用的是MySQL的最新社区版(MySQL Community Server 8.0.34)
- 下载地址:https://dev.mysql.com/downloads/mysql/
# mysql-8.0.34-winx64.zip
# 1. 解压:解压到不带中文和空格的目录,如:d:\develop\mysql-8.0.34-winx64
# 2. 配置
# 2.1 添加环境变量
# 新建系统变量 如:变量名(N):MYSQL_HOME 变量值(V):D:develop\mysql-8.0.34-winx64
# 编辑环境变量path 添加 %MYSQL_HOME%\bin
# 验证:cmd命令行 输入 >mysql 提示ERROR 20O3 (HYO00):Can't connect to MySQL server on ’localhost:3306’(10061)
# 2.2 初始化 以管理员身份打开命令行
mysqld --initialize-insecure
# 2.3 注册MySQL服务
mysqld -install
# 2.4 启动MySQL服务
net start mysql # 启动mysql服务
net stop mysql # 停止mysql服务
# 2.5 修改默认账户密码 本机mysql root密码可以设置得简单些,
# 但云端mysql root密码切不可设置得如此简单,不然会手段网络的暴力破解
mysqladmin -u root password 1234
# 3. 登录
mysql -uroot -p1234
mysql -uroot -p
exit #退出MySQL
mysql -u用户名 -p密码 [-h要连接的mysql服务器的ip地址(默认/缺省127.0.0.1) -P端口号(默认/缺省3306)]
# 4. 卸载
net stop mysql
mysqld -remove mysql
# 最后删除MySQL目录及相关的环境变量。
MySQL连接(命令行)
mysql -u用户名 -p密码 [-h要连接的mysql服务器的ip地址(默认/缺省127.0.0.1) -P端口号(默认/缺
MySQL-企业开发使用方式


1.2 数据模型
MySQL数据模型
- 关系型数据库: 建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
- 特点:
- 使用表存储数据,格式统一,便于维护。
- 使用SQL语言操作,标准统一,使用方便,可用于复杂查询。
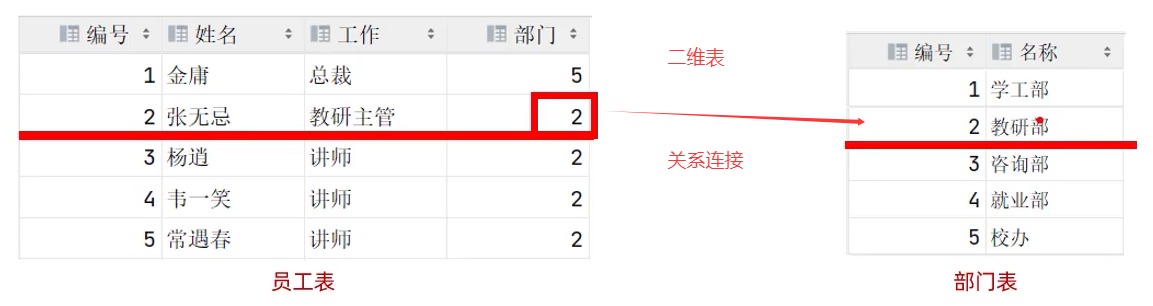
什么是关系型数据库?
- 由多张二维表组成的数据库(RDBMS)
数据是如何在数据库中存储的?
- 数据库 -> 表 -> 数据(记录)

2. SQL语句
SQL
- SQL:一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。
- 分类:
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 DBA使用 |
2.1 DDL
① 数据库-创建
- 操作语法
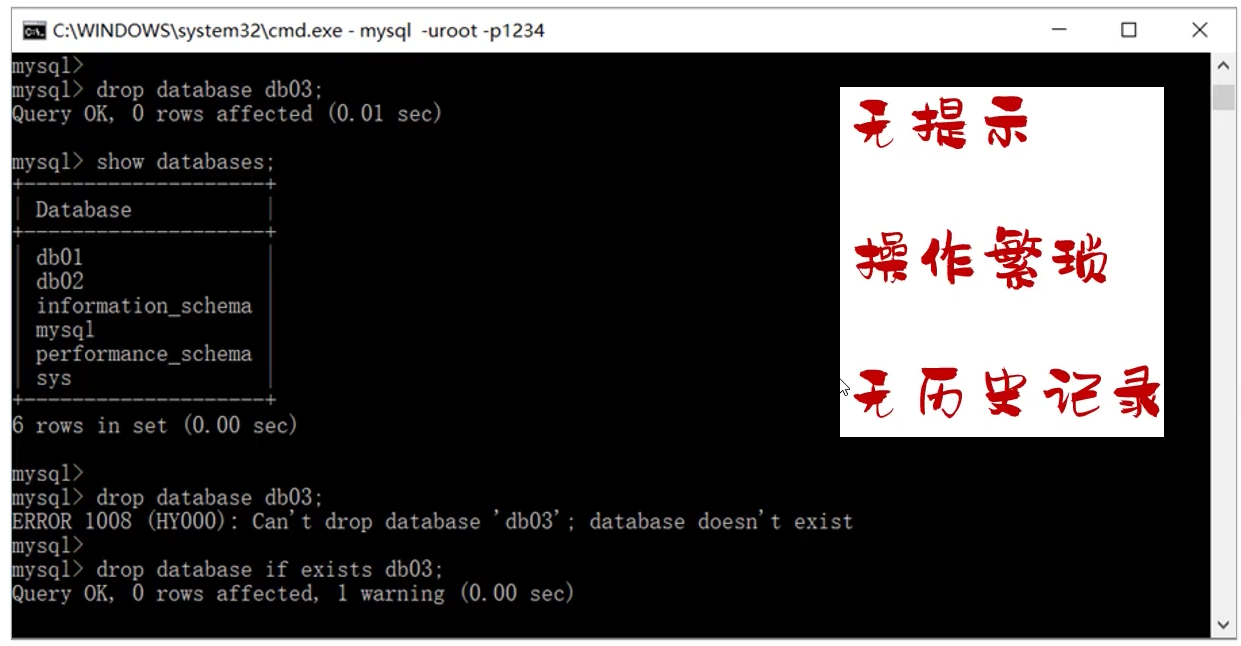
-- 查询所有数据库 语句关键字不区分大小写;分号结束
show databases;
-- 查询当前数据库
select database();
-- 使用/切换数据库
use 数据库名;
-- 创建数据库
create database [if not exists] 数据库名 [default charset utf8mb4];
-- 删除数据库
drop database [if exists] 数据库名;
- 上述语法中的database,也可以替换成 schema。如:create schema db01; MySQL8版本中,默认字符集为utf8mb4。
小结
同一个数据库服务器中,数据库的名字是否可以相同?
- 不可以
MySQL8版本默认的字符集是什么?
- utf8mb4
- default charset utf8mb4 特殊的表情符号

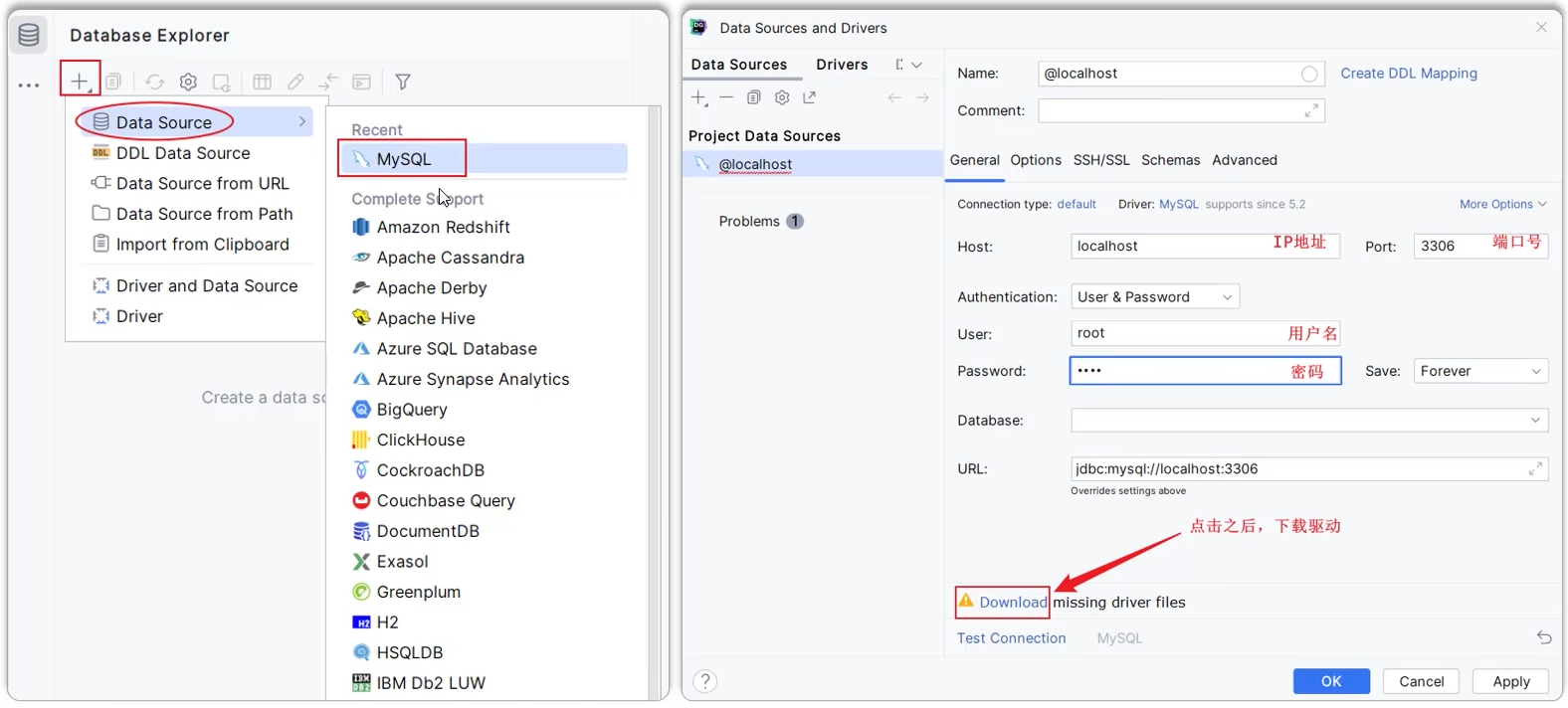
MySQL客户端工具-图形化工具

- 介绍:DataGrip是JetBrains旗下的一款数据库管理工具,是管理和开发MySQL、Oracle、PostgreSQL的理想解决方案。
- 官网:https://www.jetbrains.com/zh-cn/datagrip/
- 安装:参考资料中提供的《DataGrip安装手册》
② 表结构-创建
create table 表名(
字段1 字段类型 [约束] [comment 字段1注释],
字段2 字段类型 [约束] [comment 字段2注释],
......
字段n 字段类型 [约束] [comment 字段n注释]
)[comment 表注释];
- 约束:约束是作用于表中字段上的规则,用于限制存储在表中的数据。
- 目的:保证数据库中数据的正确性、有效性和完整性。
常见约束
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为null | not null |
| 唯一约束 | 保证字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一,一个数据表中只有一个字段能定义为主键 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段值,则采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
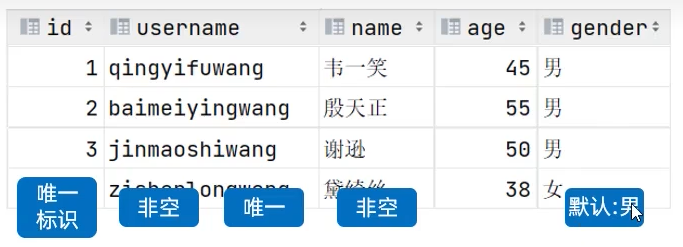
create database web02 ;
use web02;
-- 创建表
create table user(
id int comment 'ID,唯一标识',
username varchar(50) comment '用户名',
name varchar(10) comment '姓名',
age tinyint comment '年龄',
gender char(1) comment '性别'
)comment '用户信息表';
drop table user;
-- 创建表(约束)
create table user(
id int primary key auto_increment comment 'ID,唯一标识', -- 主键约束, 自增约束
username varchar(50) not null unique comment '用户名', -- 非空唯一约束
name varchar(10) not null comment '姓名', -- 非空约束
age tinyint comment '年龄',
gender char(1) default '男' comment '性别' -- 默认值约束
)comment '用户信息表';
小结
MySQL数据库中分为哪几类约束,对应的关键字是什么?
- primary key、not null、unique、default、foreign key
如何实现主键自增的效果呢?
- 定义主键的时候指定关键字 auto_increment
一个字段上是否可以添加多个约束 ?
- 可以,多个约束之间使用空格分开

DDL-表结构
- MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。
数值类型
| 类型 | 大小(byte) | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 | 备注 |
|---|---|---|---|---|---|
| tinyint | 1 | (-128,127) | (0,255) | 小整数值 | |
| smallint | 2 | (-32768,32767) | (0,65535) | 大整数值 | |
| mediumint | 3 | (-8388608,8388607) | (0,16777215) | 大整数值 | |
| int | 4 | (-2147483648,2147483647) | (0,4294967295) | 大整数值 | Java int |
| bigint | 8 | (-2^63,2^63-1) | (0,2^64-1) | 极大整数值 | Java long |
| float | 4 | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 | float(5,2):5表示整个数字长度,2 表示小数位个数 |
| double | 8 | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | 0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308) | 双精度浮点数值 | double(5,2):5表示整个数字长度,2 表示小数位个数 |
| decimal | 精确数值,财会中的单价和金额,实际是放大倍数的整数 | 小数值 | decimal(5,2):5表示整个数字长度,2 表示小数位个数 |
数值类型的选取原则: 在满足业务需求的前提下, 尽可能选择占用磁盘空间小的数据类型。age tinyint unsigned,id int unsigned
字符串类型
| 类型 | 大小 | 描述 |
|---|---|---|
| char | 0-255 bytes | 定长字符串 |
| varchar | 0-65535 bytes | 变长字符串 |
| tinyblob | 0-255 bytes | 不超过255个字符的二进制数据 |
| tinytext | 0-255 bytes | 短文本字符串 |
| blob | 0-65 535 bytes | 二进制形式的长文本数据 |
| text | 0-65 535 bytes | 长文本数据 |
| mediumblob | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| mediumtext | 0-16 777 215 bytes | 中等长度文本数据 |
| longblob | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| longtext | 0-4 294 967 295 bytes | 极大文本数据 |
| char与varchar | 优势 | 劣势 |
|---|---|---|
| char(10): 固定占用10个字符空间; 存储A, 占用10个空间; 存储ABC, 占用10个空间; | 性能略高 | 浪费磁盘空间 |
| varchar(10): 最多占用10个字符空间; 存储A, 占用1个空间; 存储ABC, 占用3个空间; | 节约磁盘空间 | 性能略低 |
username varchar(50)、idcard char(18)、phone char(11)
blob 存储二进制数据类型,一般存储在文件系统中性能更高,text文本数据类型
日期时间类型
| 类型 | 大小(byte) | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| date | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| time | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| year | 1 | 1901 至 2155 | YYYY | 年份值 |
| datetime | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| timestamp | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
bithday date,operateTime datetime
小结
1.数值类型在定义的时候,后面加了unsigned关键字是什么意思?
- unsigned表示无符号类型,表示只能取o及正数
- 不加默认是signed,表示可以取负数
2.char与varchar的区别是什么?什么时候用char,什么时候用varchar?
- char是定长字符串,varchar是变长字符串
- 如果一个字段的长度是固定的,建议使用char;如:身份证号、手机号
- 如果一个字段的长度不是固定的,建议使用varchar;如:用户名、姓名

案例:设计员工表emp
- 1.阅读并分析页面原型及需求
- 2.分析表中包含哪些字段,以及字段的类型、约束
- 3.创建表结构(添加基础字段id、create_time、update_time)
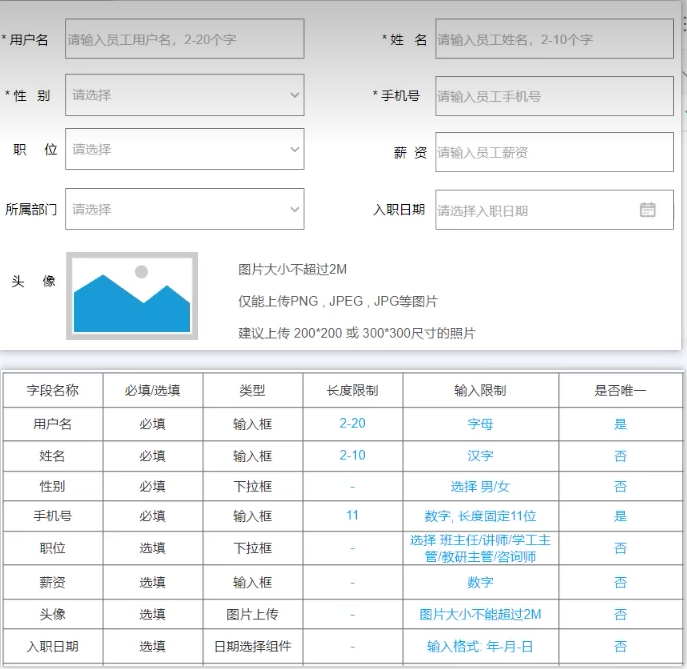
-- 案例:设计员工表emp
-- 基础字段:id主键;create_time创建时间;update_time修改时间;
create table emp
(
id int unsigned primary key auto_increment comment 'ID,主键',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别,1男;2女',
phone char(11)not null unique comment'手机号',
job tinyint unsigned comment '职位,1班主任;2讲师;3学工主管;4教研主管;5咨询师',
salary int unsigned comment '薪资',
entry_date date comment '入职日期',
image varchar(255) comment '图像',
create_time datetime comment '创建时间',
update_time datetime comment '修改时间'
) comment '员工表';
③ 表结构-查询、修改、删除
show tables; -- 查询当前数据库的所有表
desc 表名; -- 查询表结构
show create table 表名; -- 查询建表语句
alter table 表名 add 字段名 类型(长度) [comment 注释] [约束]; -- 添加字段
alter table 表名 modify 字段名 新数据类型(长度); -- 修改字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 注释] [约束]; -- 修改字段名与字段类型
alter table 表名 drop column 字段名; -- 删除字段
alter table 表名 rename to 新表名; -- 修改表名
drop table [if exists] 表名; -- 删除表
-- 使用图形化工具上述命令都可简单明了操作完成上述任务
-- 查询当前数据库所有表
show tables;
-- 查看表结构
desc emp;
-- 查询建表语句
show create table emp;
-- 字段:添加字段qqvarchar(13)
alter table emp add qq varchar(13) comment 'QQ号码';
-- 字段:修改字段类型qqvarchar(15)
alter table emp modify qq varchar(15);
-- 字段:修改字段名qq->qq_num varchar(15)
alter table emp change qq qq_num varchar(15) comment 'QQ号码';
-- 字段:删除字段qq_num
alter table emp drop qq_num;
-- 修改表名
alter table emp rename to employee;
-- 删除表
drop table employee;
注意:在删除表时,表中的全部数据也会被删除。
2.2 DML
- DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
- 添加数据(INSERT)
- 修改数据(UPDATE)
- 删除数据(DELETE)
① insert
-- 指定字段添加数据
insert into 表名(字段名1, 字段名2) values (值1, 值2);
-- 全部字段添加数据
insert into 表名 values (值1, 值2, ...);
-- 批量添加数据(指定字段)
insert into 表名 (字段名1, 字段名2) values (值1, 值2), (值1, 值2);
-- 批量添加数据(全部字段)
insert into 表名 values (值1, 值2, ...), (值1, 值2, ...);
- 插入数据时,指定的字段顺序需要与值的顺序是一一对应的 。
- 字符串和日期型数据应该包含在引号中(单引号、双引号都可以)。
- 插入的数据大小/长度,应该在字段的规定范围内 。
-- DML:数据操作语言
-- DML: 插入数据- insert
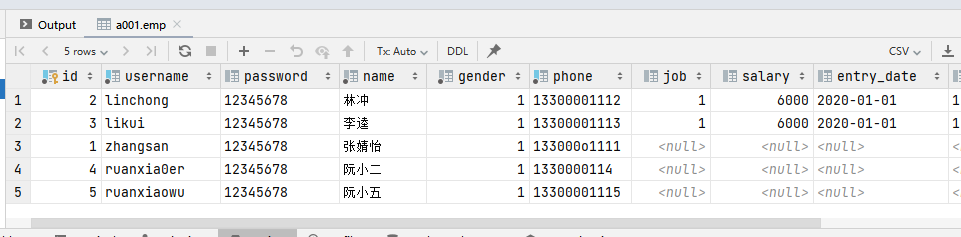
-- 1.为emp表的username,password,name,gender,phone字段插入值
insert into emp(username,password,name,gender,phone) values('songjiang','12345678','宋江',1,'133000o1111');
-- 2,为emp表的所有字段插入值
-- 方式1:
insert into emp(id, username, password, name, gender, phone, job, salary, entry_date, image, create_time, update_time)
values(null,'linchong','12345678','林冲',1,'13300001112',1,6000,'2020-01-01','1.jpg',now(),now());
-- 方式2:
insert into emp values(null,'likui','12345678','李逵',1,'13300001113',1,6000,'2020-01-01','1.jpg',now(),now());
-- 3.批量为emp表的username,password,name,gender,phone 字段插入数据
insert into emp(username, password, name, gender, phone) values
('ruanxia0er','12345678','阮小二',1,'1330000114'),
('ruanxiaowu','12345678','阮小五',1,'13300001115');
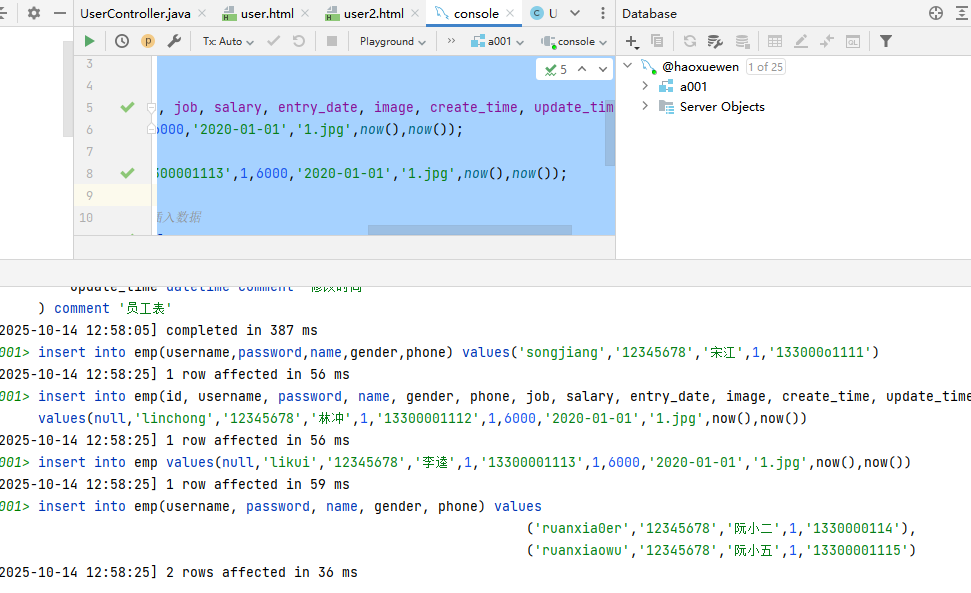
② update
-- 修改数据
update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [ where 条件 ] ;
- 修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。
-- DML:更新数据-update
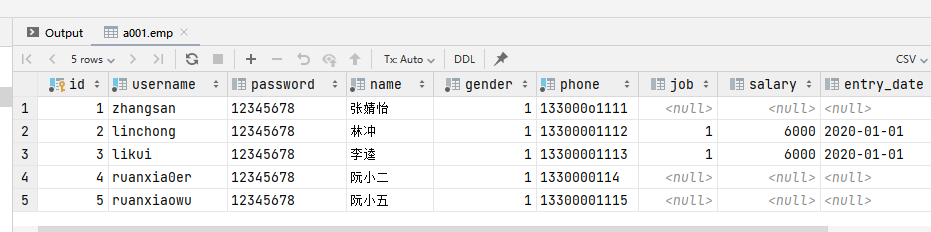
-- 1.将emp表的ID为1员工用户名更新为‘zhangsan',姓名name字段更新为‘张三'
update emp set username = 'zhangsan' , name = '张婧怡' where id = 1;
-- 2.将emp表的所有员工的入职日期更新为‘2010-01-01'
update emp set entry_date ='2010-01-01';
③ delete
-- 删除数据
delete from 表名 [where 条件];
- DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。
- DELETE 语句不能删除某一个字段的值(如果要操作,可以使用UPDATE,将该字段的值置为NULL)。
-- DML:删除数据-delete
-- 1.删除emp表中ID为1的员工
delete from emp where id=1;
-- 2.删除emp表中的所有员工
delete from emp;
2.3 DQL
- DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。
- 关键字:select 占到sql使用率的90%左右
完整的DQL语句语法:
select 字段列表
from 表名列表
where 条件列表
group by 分组字段列表
having 分组后条件列表
order by 排序字段列表
limit 分页参数

- 基本查询(select...from...)
- 条件查询(where)
- 分组查询(group by)
- 排序查询(order by)
- 分页查询(limit)
① 基本查询
-- 查询多个字段
select 字段1,字段2,字段3 from 表名;
-- 查询所有字段(通配符)
select * from 表名;
-- 为查询字段设置别名,as关键字可以省略
select 字段1 [as 别名1], 字段2 [as 别名2] from 表名;
-- 去除重复记录
select distinct 字段列表 from 表名;
*号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)。
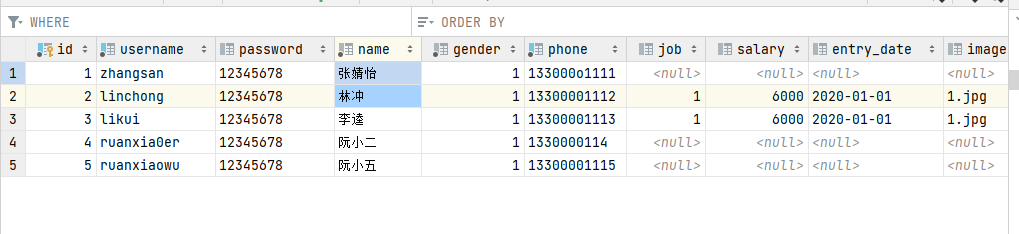
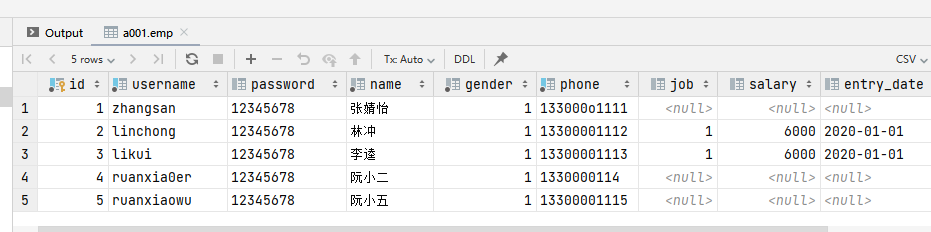
-- 准备测试数据 第1行换成自己的姓名
INSERT INTO emp(id, username, password, name, gender, phone, job, salary, image, entry_date, create_time, update_time)
VALUES (1,'zjy','123456','张婧怡',1,'13309090000',4,15000,'0.jpg','2000-01-01','2024-04-11 16:35:33','2024-04-11 16:35:35'),
(2,'shinaian','123456','施耐庵',1,'13309090001',4,15000,'1.jpg','2000-01-01','2024-04-11 16:35:33','2024-04-11 16:35:35'),
(3,'songjiang','123456','宋江',1,'13309090002',2,8600,'2.jpg','2015-01-01','2024-04-11 16:35:33','2024-04-11 16:35:37'),
(4,'lujunyi','123456','卢俊义',1,'13309090003',2,8900,'3.jpg','2008-05-01','2024-04-11 16:35:33','2024-04-11 16:35:39'),
(5,'wuyong','123456','吴用',1,'13309090004',2,9200,'4.jpg','2007-01-01','2024-04-11 16:35:33','2024-04-11 16:35:41'),
(6,'gongsunsheng','123456','公孙胜',1,'13309090005',2,9500,'5.jpg','2012-12-05','2024-04-11 16:35:33','2024-04-11 16:35:43'),
(7,'huosanniang','123456','扈三娘',2,'13309090006',3,6500,'6.jpg','2013-09-05','2024-04-11 16:35:33','2024-04-11 16:35:45'),
(8,'chaijin','123456','柴进',1,'13309090007',1,4700,'7.jpg','2005-08-01','2024-04-11 16:35:33','2024-04-11 16:35:47'),
(9,'likui','123456','李逵',1,'13309090008',1,4800,'8.jpg','2014-11-09','2024-04-11 16:35:33','2024-04-11 16:35:49'),
(10,'wusong','123456','武松',1,'13309090009',1,4900,'9.jpg','2011-03-11','2024-04-11 16:35:33','2024-04-11 16:35:51'),
(11,'lichong','123456','林冲',1,'13309090010',1,5000,'10.jpg','2013-09-05','2024-04-11 16:35:33','2024-04-11 16:35:53'),
(12,'huyanzhuo','123456','呼延灼',1,'13309090011',2,9700,'11.jpg','2007-02-01','2024-04-11 16:35:33','2024-04-11 16:35:55'),
(13,'xiaoliguang','123456','小李广',1,'13309090012',2,10000,'12.jpg','2008-08-18','2024-04-11 16:35:33','2024-04-11 16:35:57'),
(14,'yangzhi','123456','杨志',1,'13309090013',1,5300,'13.jpg','2012-11-01','2024-04-11 16:35:33','2024-04-11 16:35:59'),
(15,'shijin','123456','史进',1,'13309090014',2,10600,'14.jpg','2002-08-01','2024-04-11 16:35:33','2024-04-11 16:36:01'),
(16,'sunerniang','123456','孙二娘',2,'13309090015',2,10900,'15.jpg','2011-05-01','2024-04-11 16:35:33','2024-04-11 16:36:03'),
(17,'luzhishen','123456','鲁智深',1,'13309090016',2,9600,'16.jpg','2010-01-01','2024-04-11 16:35:33','2024-04-11 16:36:05'),
(18,'liying','12345678','李应',1,'13309090017',1,5800,'17.jpg','2015-03-21','2024-04-11 16:35:33','2024-04-11 16:36:07'),
(19,'shiqian','123456','时迁',1,'13309090018',2,10200,'18.jpg','2015-01-01','2024-04-11 16:35:33','2024-04-11 16:36:09'),
(20,'gudasao','123456','顾大嫂',2,'13309090019',2,10500,'19.jpg','2008-01-01','2024-04-11 16:35:33','2024-04-11 16:36:11'),
(21,'ruanxiaoer','123456','阮小二',1,'13309090020',2,10800,'20.jpg','2018-01-01','2024-04-11 16:35:33','2024-04-11 16:36:13'),
(22,'ruanxiaowu','123456','阮小五',1,'13309090021',5,5200,'21.jpg','2015-01-01','2024-04-11 16:35:33','2024-04-11 16:36:15'),
(23,'ruanxiaoqi','123456','阮小七',1,'13309090022',5,5500,'22.jpg','2016-01-01','2024-04-11 16:35:33','2024-04-11 16:36:17'),
(24,'ruanji','123456','阮籍',1,'13309090023',5,5800,'23.jpg','2012-01-01','2024-04-11 16:35:33','2024-04-11 16:36:19'),
(25,'tongwei','123456','童威',1,'13309090024',5,5000,'24.jpg','2006-01-01','2024-04-11 16:35:33','2024-04-11 16:36:21'),
(26,'tongmeng','123456','童猛',1,'13309090025',5,4800,'25.jpg','2002-01-01','2024-04-11 16:35:33','2024-04-11 16:36:23'),
(27,'yanshun','123456','燕顺',1,'13309090026',5,5400,'26.jpg','2011-01-01','2024-04-11 16:35:33','2024-04-11 16:36:25'),
(28,'lijun','123456','李俊',1,'13309090027',5,6600,'27.jpg','2004-01-01','2024-04-11 16:35:33','2024-04-11 16:36:27'),
(29,'lizhong','123456','李忠',1,'13309090028',5,5000,'28.jpg','2007-01-01','2024-04-11 16:35:33','2024-04-11 16:36:29'),
(30,'songqing','123456','宋清',1,'13309090029',5,5100,'29.jpg','2020-01-01','2024-04-11 16:35:33','2024-04-11 16:36:31'),
(31,'liyun','123456','李云',1,'13309090030',NULL,NULL,'30.jpg','2020-03-01','2024-04-11 16:35:33','2024-04-11 16:36:31');
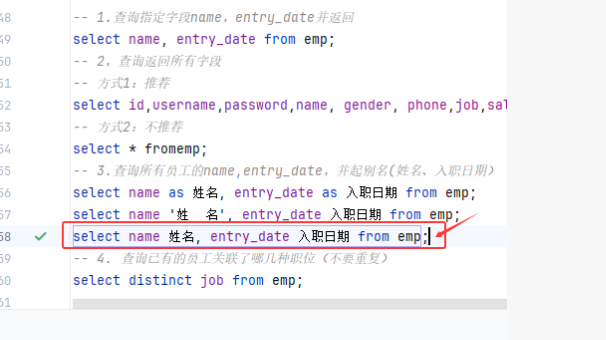
-- 1.查询指定字段name,entry_date并返回
select name, entry_date from emp;
-- 2,查询返回所有字段
-- 方式1:推荐
select id,username,password,name, gender, phone,job,salary,entry_date,image, create_time, update_time from emp;
-- 方式2:不推荐
select * fromemp;
-- 3.查询所有员工的name,entry_date,并起别名(姓名、入职日期)
select name as 姓名, entry_date as 入职日期 from emp;
select name '姓 名', entry_date 入职日期 from emp;
select name 姓名, entry_date 入职日期 from emp;
-- 4. 查询已有的员工关联了哪几种职位(不要重复)
select distinct job from emp;
小结
1.基本查询语法?select 字段列表 from 表名
2.如何为查询返回的字段设置别名? 字段名 「as] 别名
3.如何去除查询返回的重复记录? distinct

② 条件查询
select 字段列表 from 表名 where 条件列表 ;
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| between ... and ... | 在某个范围之内(含最小、最大值) |
| in(...) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| is null | 是null |
| 逻辑运算符 | 功能 | ||
|---|---|---|---|
| and 或 && | 并且 (多个条件同时成立) | ||
| or 或 \ | \ | 或者 (多个条件任意一个成立) | |
| not 或 ! | 非 , 不是 |
-- ==========DQL:条件查询===========
-- 1.查询 姓名 柴进 的员工
select * from emp where name = '柴进';
-- 2.查询薪资小于等于5000的员工信息
select * from emp where salary <= 5000;
-- 3. 查询没有分配职位的员工信息
select * from emp where job is null;
-- 4. 查询有职位的员工信息
select * from emp where job is not null;
-- 5.查询密码不等于‘123456’的员工信息
select * from emp where password != '123456';
select * from emp where password <> '123456';
-- 6.查询入职日期在‘2000-01-01'(包含)到'2010-01-01'(包含)之间的员工信息
select * from emp where entry_date between '2000-01-01' and '2010-01-01';
select * from emp where entry_date between '2010-01-01' and '2000-01-01'; -- 错误 没有数据 最小值在前、最大值在后
-- select * from emp where entry_date between '最小值' and '最大值';
-- 7.查询入职时间在‘2000-01-01'(包含)到‘2010-01-01'(包含)之间且性别为女的员工信息
select * from emp where entry_date between '2000-01-01' and '2010-01-01' and gender = 2;
select * from emp where (entry_date between '2000-01-01' and '2010-01-01') and gender = 2;
-- 8.查询职位是2(讲师),3(学工主管),(教研主管)的员工信息
select * from emp where job = 2 or job = 3 or job = 5;
select * from emp where job in (2,3,5);
-- 9,查询姓名为两个字的员工信息 (_单个字符;%任意个字符)
select * from emp where name like '__';
-- 10. 查询姓‘阮’的员工信息
select * from emp where name like '阮%';
-- 11,查询姓名中包含‘二’的员工信息
select * from emp where name like '%二%';
小结
- 1.如何进行null值的判断?
is null,is not null - 2.模糊匹配中的通配符?
%(任意个字符),_(一个字符) - 3.如何组装多个查询条件?
and /or

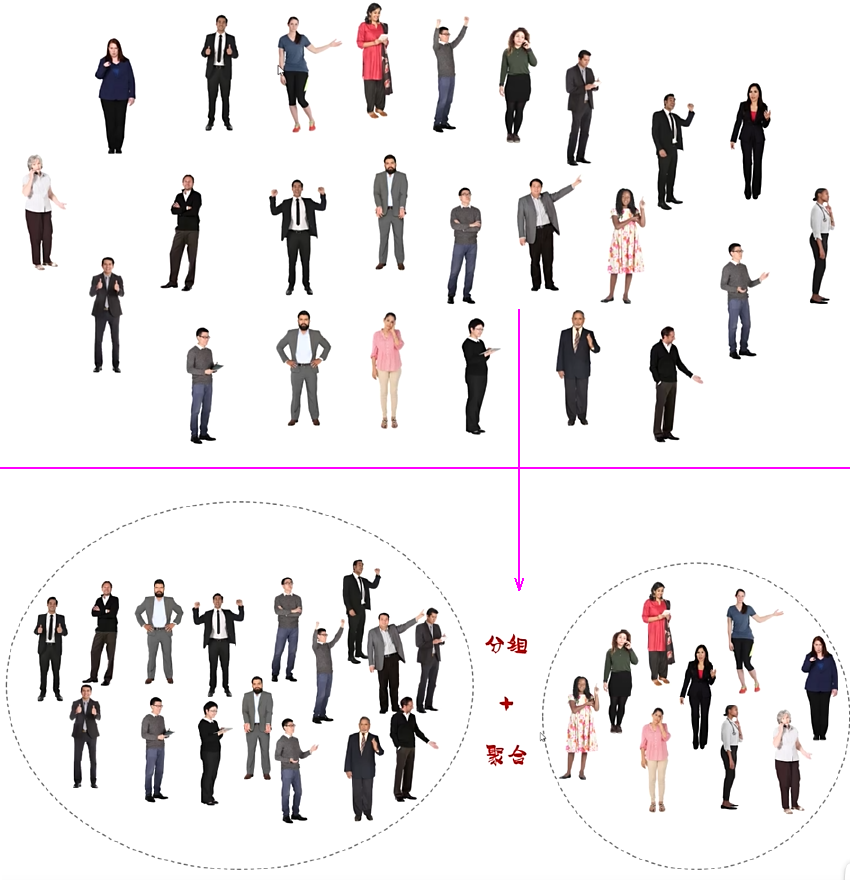
③ 分组查询
聚合函数
聚合函数:将一列数据作为一个整体,进行纵向计算。
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
注意
- null值不参与所有聚合函数的运算 。
- 统计数量可以使用:count(
*) count(字段) count(常量),推荐使用count(*) 。
-- ======DQL:分组查询======
-- 聚合函数
-- 注意:所有的聚合函数不参与null的统计
-- 1.统计该企业员工数量
-- count(字段)
select count(id) from emp;
select count(job) from emp; -- 统计非空的, null不参与统计
-- count(*):推荐 底层优化
select count(*) from emp;
-- count(常量) 推荐
select count(1) from emp;
select count(0) from emp;
select count(-1) from emp;
-- 2.统计该企业员工的平均薪资
select avg(salary) from emp;
-- 3,统计该企业员工的最低薪资
select min(salary) from emp;
-- 4.统计该企业员工的最高薪资
select max(salary) from emp;
-- 5,统计该企业每月要给员工发放的薪资总额(薪资之和)
select sum(salary) from emp;
分组查询
select 字段列表 from 表名 [where 条件列表] group by 分组字段名 [having 分组后过滤条件];
where与having的区别:
- 执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
注意
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
- 执行顺序: where > 聚合函数 > having 。
-- 分组
-- 注意:分组之后,select后的字段列表不能随意书写,能写的一般是分组字段+聚合函数;
-- 1,根据性别分组,统计男性和女性员工的数量
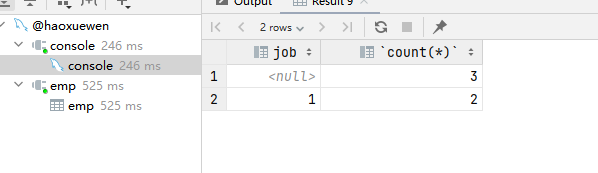
select gender, count(*) from emp group by gender;
-- 2,先查询入职时间在‘2015-01-01’(包含)以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
select * from emp where entry_date <= '2015-01-01'; -- 先进行条件查询
select job, count(*) from emp where entry_date <= '2015-01-01' group by job; -- 再进行分组查询
select job, count(*) from emp where entry_date <= '2015-01-01' group by job having count(*) >= 2; -- 最后过滤分组查询后的结果

④ 排序查询
select 字段列表 from 表名 [where 条件列表] [group by 分组字段名 having 分组后过滤条件] order by 排序字段 排序方式[, 排序字段2 排序方式2];
- 排序方式:升序(asc),降序(desc);默认为升序asc,是可以不写的。
- 如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序。
-- ===== 排序査询=======
-- 1,根据入职时间,对员工进行升序排序
select * from emp order by entry_date asc;
select * from emp order by entry_date;
-- 2,根据入职时间,对员工进行降序排序
select * from emp order by entry_date desc;
-- 3,根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序
select * from emp order by entry_date, update_time desc;
-- 4,根据职位和入职时间对员工进行排序
select * from emp order by job, entry_date;

⑤ 分页查询
select 字段 from 表名 [where 条件] [group by 分组字段 having 过滤条件] [order by 排序字段] limit 起始索引,查询记录数;

- 起始索引从0开始 。
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是LIMIT 。
- 如果起始索引为0,起始索引可以省略,直接简写为 limit 10 。
-- ======分页查询===
-- 1.从起始索引0开始查询员工数据,每页展示5条记录
select * from emp limit 0,5;
select * from emp limit 5;
-- 2.查询第1页员工数据,每页展示5条记录
select * from emp limit 0,5;
-- 3.查询第2页员工数据,每页展示5条记录
select * from emp limit 5,5;
-- 4.查询第3页员工数据,每页展示5条记录
select * from emp limit 10,5;
-- 页码 起始索引=(页码 ̄1)* 每页展示记录数
小结
DQL语句中的分页查询
- 语法:limit起始索引,每页展示记录数
- 注意:项目开发中,前端传递过来的是页码,需要转换为起始索引
- 公式:(页码-1)x 每页展杂记录数

①②③④⑤⑥⑦⑧⑨⑩